
The DISTINCT clause in a query can help us quickly remove duplicates from our results. Sometimes it can be beneficial to stop and ask why. Why do we need to use the clause, why are we receiving duplicates from our data?
I see this typically due to a JOIN being used where we don’t really want all of those results. This could be a ‘does something exist’ check such as if a customer has ever ordered before. The issue comes when there are multiple rows returned like a frequent customer in this example.
Using the DISTINCT clause can add overhead to our query whilst also hiding understanding we have of our data. Rewriting the query can make it clearer and help the engine to tackle it more efficiently.
Distinct dilemma
Let’s take a look at a query using AdventureWorks (2019) data. We want to find all those crazy customers who purchase items in Electric Pink to try and sell them our new Luminous Lime products:
SELECT
DISTINCT
c.CustomerID,
c.AccountNumber
FROM
Sales.Customer c
INNER JOIN Sales.SalesOrderHeader h ON c.CustomerID = h.CustomerID
INNER JOIN Sales.SalesOrderDetail d ON h.SalesOrderID = d.SalesOrderID
INNER JOIN Production.Product p ON d.ProductID = p.ProductID
WHERE
p.Color = 'Electric Pink';
Looking at these tables we can guess there may be multiple orders per customer and we’ll have orders which contain multiple products. Without the DISTINCT in this query we’ll have duplicate rows returned if a customer has purchased more than one electric pink product. How could they resist.
Taking a quick step back from this, here’s what the execution plan looks like without the DISTINCT being used:
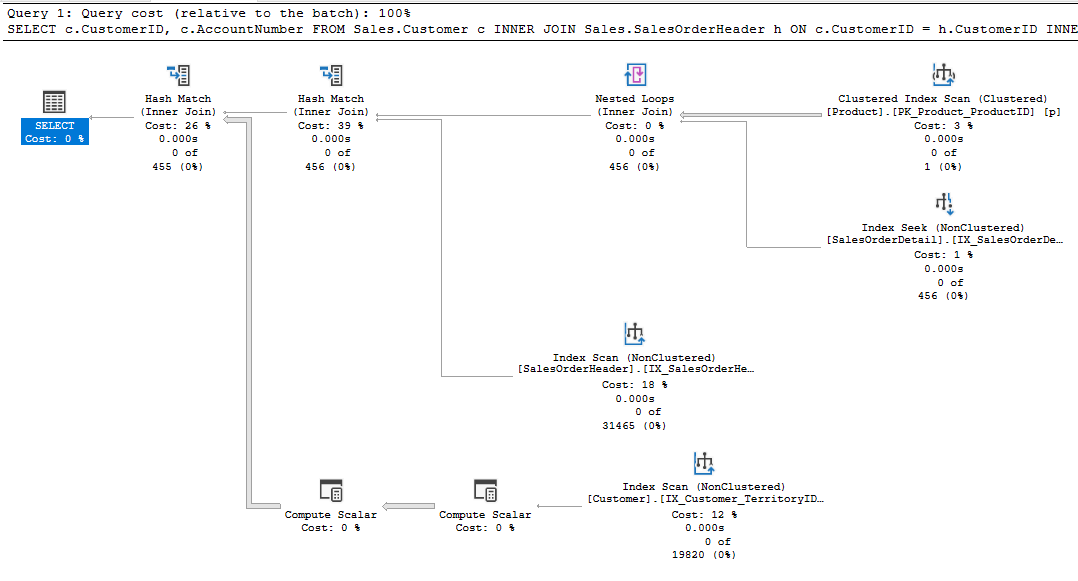
Now because we want to avoid those duplicates we’ll add the DISTINCT clause and see the impact (highlighted) below on the plan:

Whilst our data may return in good time our plan has now grown. We’ve got an a new Distinct Sort operator which has been added. This can impact the performance of our query including increased CPU usage and a larger memory grant.
It’s worth noting here that it won’t always be a Sort operator which will pop into your plan. Depending on the volume and shape of the data you could see other operators such as Hash Match.
Alternative solution
Now let’s look at an alternative approach.
In this query we aren’t concerned with a customer purchasing a single item or multiple which meet our criteria. One will be sufficient. We can therefore replace this logic with an EXISTS check which doesn’t need to return all of those records for us.
A version of the query with this change would look like:
SELECT
c.CustomerID,
c.AccountNumber
FROM
Sales.Customer c
WHERE
EXISTS (
SELECT 'exists'
FROM Sales.SalesOrderHeader h
INNER JOIN Sales.SalesOrderDetail d ON h.SalesOrderID = d.SalesOrderID
INNER JOIN Production.Product p ON d.ProductID = p.ProductID
WHERE c.CustomerID = h.CustomerID
AND p.Color = 'Electric Pink'
);
The plan produced by this query now looks closer to where we started:
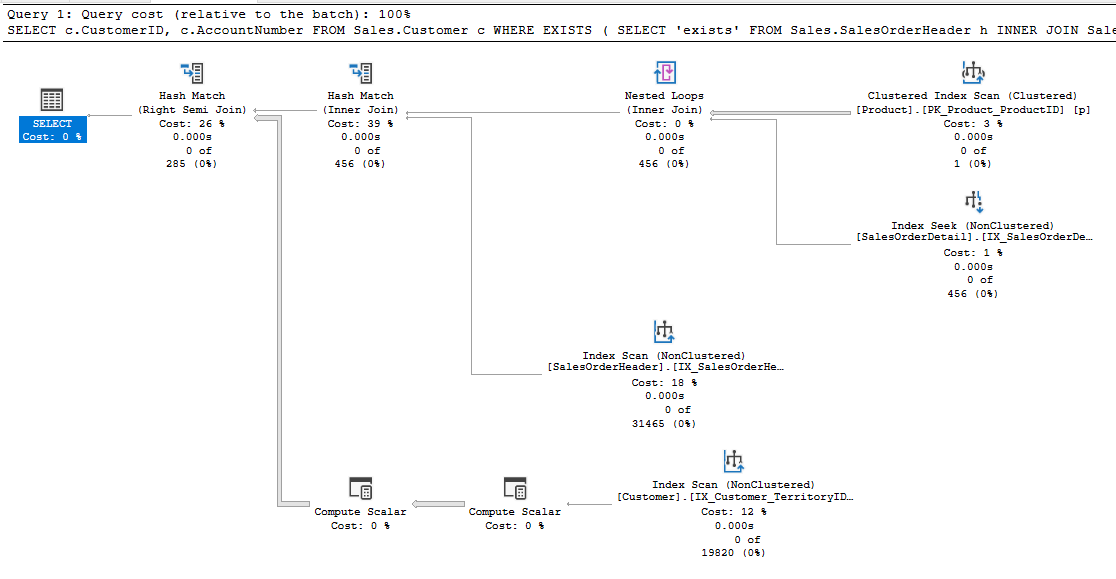
This plan has removed the Distinct Sort which we had previously so it’s now the same shape as where we started but without duplicate records being returned. Whilst it’s the same shape it isn’t using the same operators though.
The original plan returned results from a Hash Match operator which used an Inner Join so we’d return all (duplicate) records. Our new plan uses a Semi Join which simply checks for the existence of matching records. This is due to the EXISTS operator only needing to know if there are matching records from the top branch in our plan, regardless of what or how many there are. You can see the row estimate for the operator have decreased to reflect this.
Wrap up
Whilst a DISTINCT clause may provide the solution to removing duplicate records from our results, it isn’t always the right approach. Restructuring the query as we’ve done here can better explain what we’re trying to achieve and also produce a simpler plan to execute.
Depending on the underlying data the use of DISTINCT may be needed so it isn’t always appropriate to refactor it out of a query. We should try to use the approach which better explains to the engine the logic we want to implement based on what we know about our data and the engine may not.

4 replies on “Optimising DISTINCT Clauses using EXISTS”
[…] Andy Brownsword makes a switch: […]
To be honest – using WHERE EXISTS instead of DISTINCT is not “optimizing the distinct” but writing the query the correct way – even if it is a common mistake to use joins when you just want to know if something EXISTS.
Or writing IF (SELECT COUNT(*) FROM dbo.tbl) > 1 instead of IF EXISTS (SELECT * FROM dbo.tbl) – it may be even more common.
Besides the duplicates an EXISTS prevents it is often faster, since it stops after the first match, while the other queries may need to read thousand orders / posts / comments / whatever and joining all the stuff together (with a bit bad luck it is too much for the reserved memory because parameter sniffing and has to do a slow spill to tempdb – which you can prevent with the EXISTS.
Hey! Thanks for the feedback!
The idea for this post came from some code where I saw the DISTINCT being used as a crutch. As you say writing the query the correct way was the answer which is what I wanted to demonstrate.
I wasn’t clear in mentioning it stopping after the first match even if I hinted at it in a couple of places. Thank you for making that point more clearly.
[…] Try using EXISTS instead if the query uses DISTINCT as a crutch […]