
Blocking in SQL Server will reduce throughput. Excessive blocking can be cause bottlenecks on our environments so helping to mitigate it. Here we’re going back to basics to look at how it happens and how having effective indexes can reduce it.
Blocking
We’ll start off with an example of blocking. Here’s our customer table and a couple of records to demonstrate:
CREATE TABLE dbo.Customers (
CustomerID INT IDENTITY(1, 1),
StoreID INT,
LastTransaction DATE,
Balance MONEY,
CONSTRAINT PK_Customers PRIMARY KEY (CustomerID)
);
INSERT INTO dbo.Customers
VALUES (1, '2024-01-01', 0),
(2, '2023-12-01', 4.99);
Now we’ll start a transaction running to update one of the Customer records:
BEGIN TRAN
UPDATE dbo.Customers
SET LastTransaction = '2024-02-06'
WHERE CustomerID = 1;
At the same time we’ll try to check the number of customers per store:
SELECT StoreID, Customers = COUNT(CustomerID)
FROM dbo.Customers
GROUP BY StoreID;
…and we wait.
The update has blocked our query. This is because we’re trying to check the details for all customers, however a separate transaction is updating the details for Customer 1. We can use sp_WhoIsActive to see what’s going on here:
EXEC dbo.sp_whoisactive @get_locks = 1;

We only have a single copy of our data – our clustered primary key. Due to this both the UPDATE and SELECT have no choice but to use the same copy of data. If we look at our query trying to read data we’ll see it attempting to acquire Shared locks:

However they can’t be acquired due to the UPDATE statement which already has an Exclusive lock on Customer 1 in the clustered index:

Unblocking
Our issue here is that both of the queries require the same object – our clustered index – as they have no alternative. The UPDATE query requires Exclusive access so the SELECT can’t complete until that transaction has finished.
Here’s what our query plan looks like for the SELECT. We can see that it has to used the clustered index:

We can help this situation by adding an additional index. Let’s add an index on the StoreID field and include the CustomerID:
CREATE INDEX IX_StoreID
ON dbo.Customers (StoreID)
INCLUDE (CustomerID);
This will create a separate copy of that data which will be consistent with the clustered index, but will only contain the fields we’ve specified.
This copy of the data can be accessed and locked independently. This means that whilst the update takes place on our clustered index PK_Customers our SELECT can read our new IX_StoreID index.
If we run our UPDATE and SELECT at the same time now we have a different result:

Our UPDATE transaction is still running, but we’re able to query the data. If we look at the query plan for our SELECT with the new index in place, we can see it prefers to use that:

Finally if we go back to looking at locks for the still-running UPDATE transaction:

The locks on the clustered index are identical. The important point is what we don’t see. The update doesn’t need to lock our new index. This is due to our index not containing any data which will change from our UPDATE statement.
Indexing
Here we’ve looked at a very simplified version of the issue. We only have Exclusive access on a single record. The impact of blocking can grow as locks escalate and may lock an entire index or table.
I’ve referred to ‘effective’ indexing. Indexing and index choices are a broad subject. A key point to take away is that our new index completely satisfied the query. This can be referred to as a Covering Index as it completely covers all data required from that table.
If we were to use the same UPDATE statement above but we wanted to use another field not in our index:
SELECT StoreID,
Customers = COUNT(CustomerID),
Balance = SUM(Balance)
FROM dbo.Customers
GROUP BY StoreID
We’re back to this situation. The reason is that we can only get so much of the data from our index. We’re still reliant on our clustered index to lookup the Balance value:
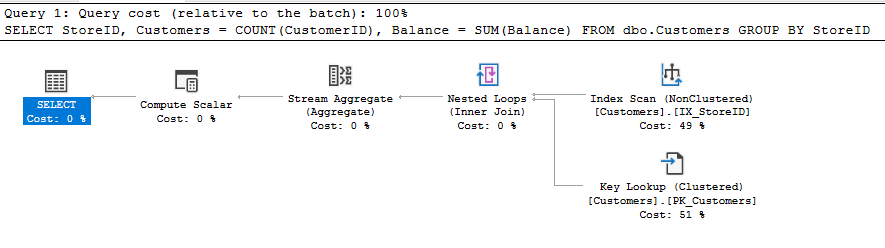
We still have Customer 1 with the record locked due to the update. This time it’s blocking our key lookup on that index.
This is why the title of the post is how effective indexing can avoid blocking.
As mentioned, indexing is a broad subject. This example isn’t to demonstrate that the Balance value should go into the index too, it’s simply to show that different situations will need different considerations.
Wrap up
In this post we’ve looked at how blocking manifests in a query and how having appropriate indexes to cover the needs of the query can avoid it.
We’ve seen how blocking occurs when queries are locking the same resource. We’ve looked at how we can see the locks and how using an index can avoid the contention.
Indexing is a very broad subject. Blocking is too. Indexing is one way to alleviate blocking but it isn’t the only one. Hopefully this gets some ideas flowing for those newer to the concept.

2 replies on “How Effective Indexing Can Avoid Blocking”
[…] Andy Brownsword removes a blocker: […]
[…] Apply covering indexes which are very beneficial in the right conditions […]