
Both TOP (1) and MAX can be used to identify the largest value in a data set. Whilst they get the same result it isn’t necessarily in the same way.
Firstly, what is the difference between the two?
The TOP clause limits the number of results which are returned from a query, in this instance we’re focussing on a single result. In contrast, when using MAX we’re applying a function to our data to select the largest value from our data.
Let’s dive into some examples with the StackOverflow data, specifically the Votes table.
Clustered data
We’ll start with a clustered primary key as a simple example. We know the Id field is unique so should be easy to determine the highest in the table:
SELECT TOP (1) Id
FROM dbo.Votes
ORDER BY Id DESC;
SELECT MAX(Id)
FROM dbo.Votes;
Both of them provide the correct result but how did they do it?
Firstly the TOP query. This does a backwards scan on the clustered index, takes the first record and it’s done. No memory grant, zero CPU time and only 4 logical reads:

We have a similar result with the MAX function. The query plan uses a Stream Aggregate to identify the maximum value. With the Id being unique the plan knows it can take the Top value to pass to the aggregate. Again we have no memory grant, CPU time, and only 4 logical reads:

Supporting index
Next up we’ll look at a non-clustered index which supports our query. We’ll use this index:
CREATE INDEX PostId_UserId
ON dbo.Votes (PostId, UserId);
We’ll see how that index helps out with these queries:
SELECT TOP (1) UserId
FROM dbo.Votes
WHERE PostId = 11227809
ORDER BY UserId DESC;
SELECT MAX(UserId)
FROM dbo.Votes
WHERE PostId = 11227809;
The data is ordered by the PostId and then UserId so we should be able to jump to the right place in the index similar to the clustered index above.
The query with the TOP clause looks much the same. This time we can see an Index Seek with a seek predicate of our PostId followed by a Backward scan of UserIds to get the result. Again we see zero CPU time, no memory grant, and the same 4 logical reads:

Similar story for the MAX function. We’ve still got no CPU time, memory grant and 4 reads. The Clustered Index Scan has also been replaced by an Index Seek based on the PostId with a Backward scan to get the largest UserId:

Partially supporting index
Next up we’ll look at data where the ordering doesn’t match our queries. This gets a little uglier.
We’ll take the last index and replace it with a new one which has the UserId as an included field rather than one of the key columns:
CREATE INDEX PostId_Inc
ON dbo.Votes (PostId)
INCLUDE (UserId);
This will mean ordering isn’t guaranteed for the users so the engine will need to take a different approach. We’ll use the exact same queries:
SELECT TOP (1) UserId
FROM dbo.Votes
WHERE PostId = 11227809
ORDER BY UserId DESC;
SELECT MAX(UserId)
FROM dbo.Votes
WHERE PostId = 11227809;
The query with the TOP clause has now lost the Top operator. This is due to the data not being delivered in order. The Index Seek can now find the post but needs to return all users as they aren’t in any specific order. The Top operator is replaced by a Top Sort operator to order the UserIds and return the top value:
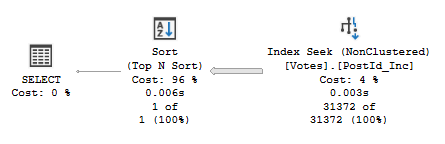
In terms of the performance we’re now doing 74 logical reads since we need to grab all UserIds from the index. We also need a memory grant of 1mb for the Sort operator. This results in 15ms of CPU time being required for this approach.
We have a change to our MAX plan too. We need to do the same Index Seek returning all UserIds. In this instance however we pass them through a Stream Aggregate to perform the MAX function and it’ll squash those to get the largest result:
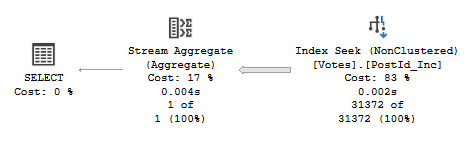
We still need to perform 74 logical reads due to taking all UserIds from the index. This approach doesn’t require a memory grant however. With the Aggregate for this being more efficient for this task than a Sort this query completes with zero CPU time required too.
No index whatsoever
Finally we’ll take this to the extreme and look for a field of which the data is completely sorted and not contained within an index at all. This should be fun:
SELECT TOP (1) VoteTypeId
FROM dbo.Votes
ORDER BY VoteTypeId DESC;
SELECT MAX(VoteTypeId)
FROM dbo.Votes;
Now we expect this to need some heavy lifting and it does indeed. Both queries need to scan the entire clustered index.
The query with the TOP clause takes the same approach as last time and uses a Sort operator to order the data before taking the Top value. Due to the work involved we can see the query went parallel:

Outside of reading the whole table, this query had a 1mb memory grant and used 48s of CPU time on my system.
The MAX query fared similarly. It used the Stream Aggregate operator as in previous examples. In fact, twice this time as the first ones happened in parallel and the output from those was then aggregated to return the result:

This version of the query also read the entire table. It also needed a memory grant this time, a mighty 136kb, and needed 39s of CPU time to complete the query.
Wrap up
In this post we’ve compared using the TOP clause and MAX function to retrieve the highest value under different scenarios. These can broadly be bundled into ordered or unordered data.
The ordered data is when we have an index where the value we’re searching is one of the keys and we can isolate that selection so we don’t need to perform any additional sorting. We used a clustered and non-clustered example here.
The unordered data is when we either don’t have an index, or the index doesn’t return data in an order which we need to grab the highest value. The examples here were a partially supporting index, and no index which resulted in a table scan.
When dealing with ordered data performance is effectively identical as we don’t need to perform additional processing. When the data is not sorted it will require additional processing such as the Sort and Stream Aggregate operators as demonstrated.
In our examples we’ve seen the Sort operator require additional memory and therefore the TOP clause is slightly less performant in like for like scenarios. Regardless of which option you choose, having ordered data is much more impactful in terms of performance.

2 replies on “Comparing Performance of TOP vs. MAX”
[…] Andy Brownsword breaks out the stopwatch: […]
[…] In the last post we looked at how TOP and MAX operators compared. We saw the execution plan for a MAX function used a Stream Aggregate operator which is one of two which we can use for aggregation […]