
Being a Data Engineer, this month’s invitation from Meagan resonates. She’s asked us to share a tip, technique, or lesson about detecting changes – which can be crucial to reduce workload across a large dataset.
I’ll rewind back a number of years to an overnight batch process which ingested key transactional data for a business. Due to their processes, the data covered a rolling year as records could be modified.
The issue: there was no indicator of which records had been modified and as a result the process took way too long, and downstream reporting wasn’t available on time.
After reviewing and stepping through the process it became clear that the vast majority of data didn’t change. This was a daily process handling 12 months of data, yet over 99% had no changes at all. However the process ingested the whole dataset (~250m records) and processed it in SQL.
Each run was:
- Read 12 months of data from flat files – every night, regardless of what has changed
- Transfer 12 months of data to the database – more data, more latency, and way more IO hammering the transaction log
- Upsert the whole dataset – 250 million rows, 99% of which haven’t changed
Processing this daily was brutal.
The goal was clear: identify what had changed as early as possible and remove 99% of records from the workflow.
The solution was simple: Hashing
By generating a hash of the whole record when reading the file, we can quickly compare the business key and hash to existing records from the database. If the business key doesn’t exist, it’s a new record. If the hash has changed for the key, the record has been updated. If neither of those are true, there’s no change and we can drop the record from the ETL, eliminating the 99% of redundant data.
Through this comparison we could filter 99% of the records at source, so we didn’t need to transfer, store, or attempt to update the whole volume of records in the database.
Hashing isn’t free, especially with this volume of data. It’s CPU intensive compared to streaming data from a file into the database. This approach also needed 12 months of hashes retrieved from the database to compare. Both of these overheads aren’t trivial. In this case:
- Hashing is expensive but as we’d quantified the volume of data being filtered, it would more than cover its overhead through optimisation. It may have been a different solution if the volume was closer to 10%
- Existing hash list from the database may be large, but also narrow as it only requires a business key and hash value. It’s extra memory and retrieval, but relatively lightweight for the benefit it brings
The result of this change was the process time reducing from 8 hours to ~30 minutes.
Here’s a sketch of the before and after process flows:
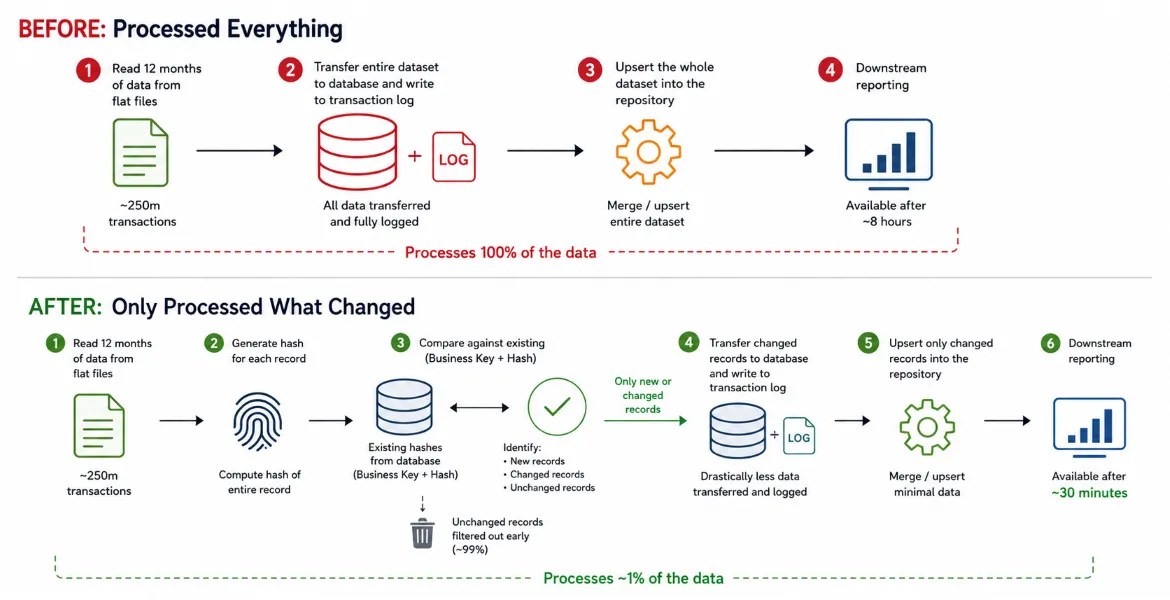
The key takeaway here isn’t hashing – it was identifying unnecessary work early and eliminating it from the pipeline. It was also quantifying how much work could be removed, allowing us to evaluate which solution would be most effective.
In this instance, hashing was a strong fit. Other solutions may lean on temporal tables, watermarks, or completely different patterns. The important part is understanding where change detection belongs in the process, and reducing unnecessary work as early as possible.
This subject is very close to my heart so I’m looking forward to seeing what the data (and engineering) communities share this month.

One reply on “T-SQL Tuesday #198 – Change Detection”
[…] Andy Brownsword builds a hash key: […]